Fine-tuning an LLM to write docs like it's 1995
Posted by taubek 5 days ago
Comments
Comment by v1ne 5 days ago
Negative example: I was looking into the German manual of my Canon EOS R5 II, and it is just fluff. Hundreds of pages, full of white space, telling me about features without actually explaining what they mean. Awful automatic translations. Their manuals used to be good (looking at my EOS 6D). But these days: oh boy.
Comment by _the_inflator 5 days ago
At that moment I felt sorry for this company, very sorry. How can you have so much disrespect for your customers? Does anyone in the physical world talk like this or do you marketing guys want to be talked to in such terms?
Brutal.
Comment by MichaelZuo 4 days ago
And unless you are above the 99th percentile of the customerbase… that’d probably be a correct guess?
Heck they could directly write “You Peons!” and still probably retain most of their customer base… if the price to performance ratio was sufficiently better than the next best competitor.
Most people care so little about the refinement of anything else nowadays.
Comment by jack_pp 4 days ago
Comment by MichaelZuo 2 days ago
Comment by theletterf 5 days ago
I also wrote on what I think makes docs beautiful, by the way! https://passo.uno/what-makes-docs-beautiful/
Comment by bebna 5 days ago
But if you look how much manuals get ignored by the customer, it doesn’t make sense to put work into them.
It is much better to let a YouTuber do it, by lending them the product and throw small amount of money against them.
Manuals are just there for legal or certifications requirements these days.
Comment by ricardobeat 5 days ago
When was the last time you met a good technical writer? It’s a vanishing profession.
Comment by embedding-shape 5 days ago
Comment by kjellsbells 4 days ago
Since good documentation creates a consistent mental model in the reader, cultural affinity of the writer to both source (developer) and reader helps, and the old, much smaller, computer industry was able to pull that off. I sat two cubes from my doc writer and we shared the same cultural worldview with each other and our market. It's much easier to communicate in that milieu because so much can be left unsaid.
Its possible that we are entering a Golden Age of Text, where everyone realizes that they have to feed their AI with decent information in order to have any hope of it producing good answers (especially true for complex technical products and internal corporate processes). But I am not hopeful.
Comment by fallinditch 4 days ago
Comment by theletterf 4 days ago
Comment by vintagedave 5 days ago
I'd really like to see the Win2K-style docs on REST, for example.
Edit: it was right there, in bold, too. https://gist.github.com/theletterf/0b8ee1112fbd087f3141d0cad...
Comment by theletterf 5 days ago
Comment by vintagedave 4 days ago
Comment by hanzeweiasa 5 days ago
Comment by wxw 4 days ago
Wonderful! Thanks for the introduction to this resource.
Comment by paultopia 4 days ago
Comment by krapht 4 days ago
Basic rag is almost stupid in how easy it is, though. You grep for keywords, take the surrounding paragraph, then stuff it all into your llm prompt.
The next upgrade is to automate keyword extraction by putting your documents into a vector store and search by vector similarity.
Comment by mybbor 4 days ago
I jumped in and added working minimize/maximize/close buttons, a draggable window, and a Start menu, because of course. Brought back memories of young me learning Visual Basic to make AOL add-ons.
https://artdirectiondaily.com/issues/2026-06-05-docs-find-a-...
Comment by theletterf 4 days ago
Comment by mybbor 4 days ago
Comment by fga_qwrh 4 days ago
LLMs work for half page answers of targeted questions. All longer prose is like swimming through molasses.
Comment by mock-possum 5 days ago
Is that why though? You need a beast of a machine to run a functional local model in my experience.
I think the big part is there’s significant sticker shock to buying capable hardware.
That said,
> weekend. I chose to try fine-tuning on two models, Llama 3.1 8B Instruct and Qwen 2.5 7B Instruct. At their size (around 8B) they run comfortably on a MacBook Air
Perhaps I spoke too soon?
Anyway
> I chose the Microsoft collection as the source of training materials. The collection contains out-of-print docs published between 1977 and 2005: more than 37 million words, covering old systems and SDKs
this strikes me as a very specific brand of 1995’s prose, spanning about 30 years. It’s a cool article though, so maybe that’s a forgivably clickbaity title.
Comment by mschild 5 days ago
Obviously not the largest, up-to-date models but for what I expect most people use them for, even on hn, there are some shockingly good models that dont require €4k machines.
I have a desktop with an AMD 6900XT and 5600 with 32GB ram. Obviously no slouch but its several years old at this point. I can comfortably run qwen 3.5 9b and get a speedy 60 token/sec output with decent results.
Comment by mock-possum 5 days ago
Is there some secret I’m missing? I’ve tried rolling my own harness, and tried a few of the ones the cool kids use - I think pi was the most recent. Not quite my tempo, I’m afraid.
Comment by mschild 5 days ago
The easiest way I have found is to use LM Studio, grab the model you want, and point whatever tooling you're using at the local exposed API.
You will have to configure the model params (temperature, etc) a bit to get the style you're expecting but it works decently well for me.
Comment by visha1v 5 days ago
Comment by OJFord 5 days ago
It's probably a fair approach to say the significant influence (training dataset) on writing at a particular time is the preceeding 30 years' material? It's certainly not only what's already written that year (nor anything since).
Comment by theletterf 5 days ago
Comment by axus 4 days ago
Comment by theletterf 4 days ago
Comment by shye 4 days ago
Comment by ethanlearns 4 days ago
Comment by holoduke 5 days ago
Comment by hgoel 4 days ago
Comment by Autious 5 days ago
Am I the only one feeling this way?
Comment by layer8 5 days ago
Comment by Autious 4 days ago
There's just so much shitty technical documentation out in the world.
Comment by jraph 5 days ago
Is there anything else you'd like to ask me?
Comment by idonotknowwhy 4 days ago
Also make sure the shape of the paragraphs is completely uniform.
Comment by Am4TIfIsER0ppos 4 days ago
Comment by perching_aix 5 days ago
The other case is when I - gasp - do something myself, and the docs are actually reasonable / easy to reference. There are workflows where me doing the thing is just plain faster still, even when including hitting up the docs real quick.
Comment by badsectoracula 4 days ago
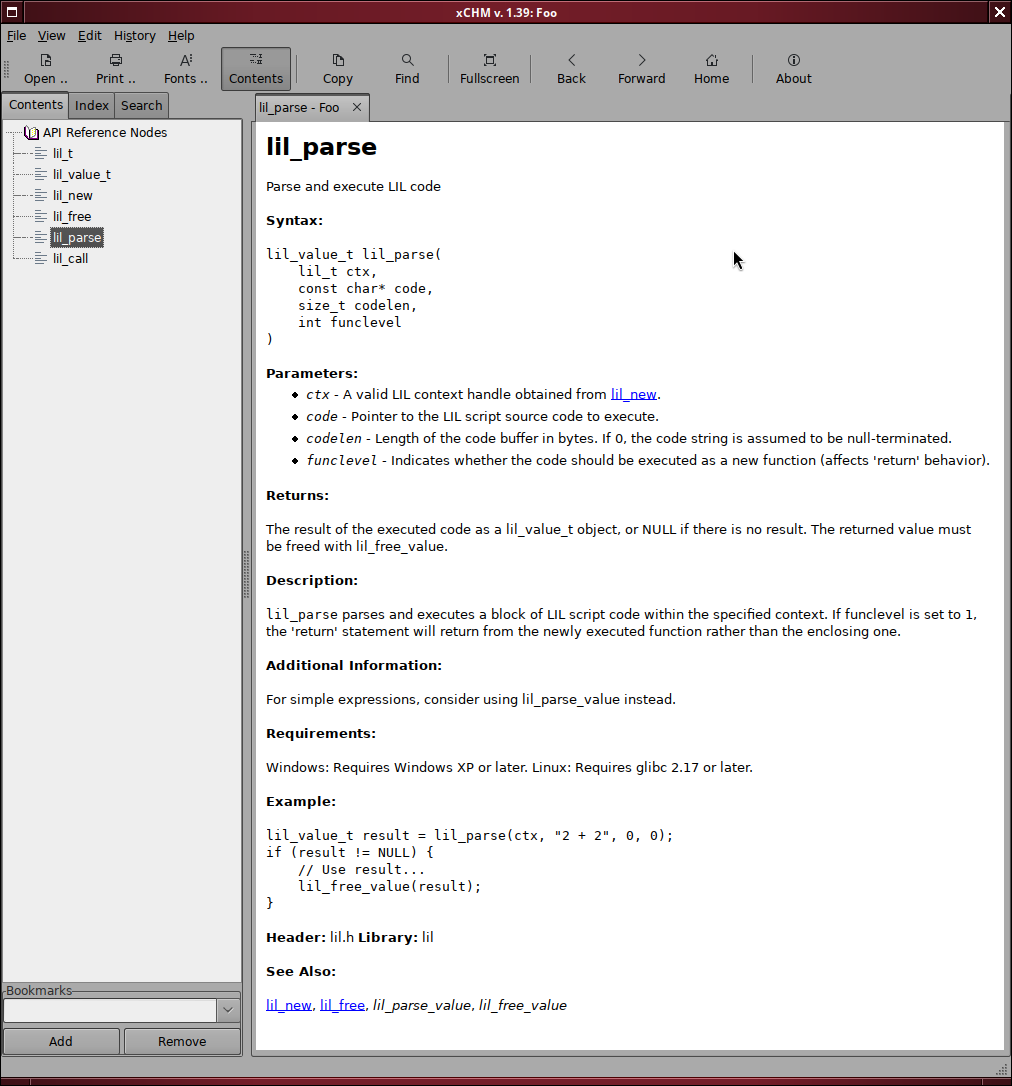
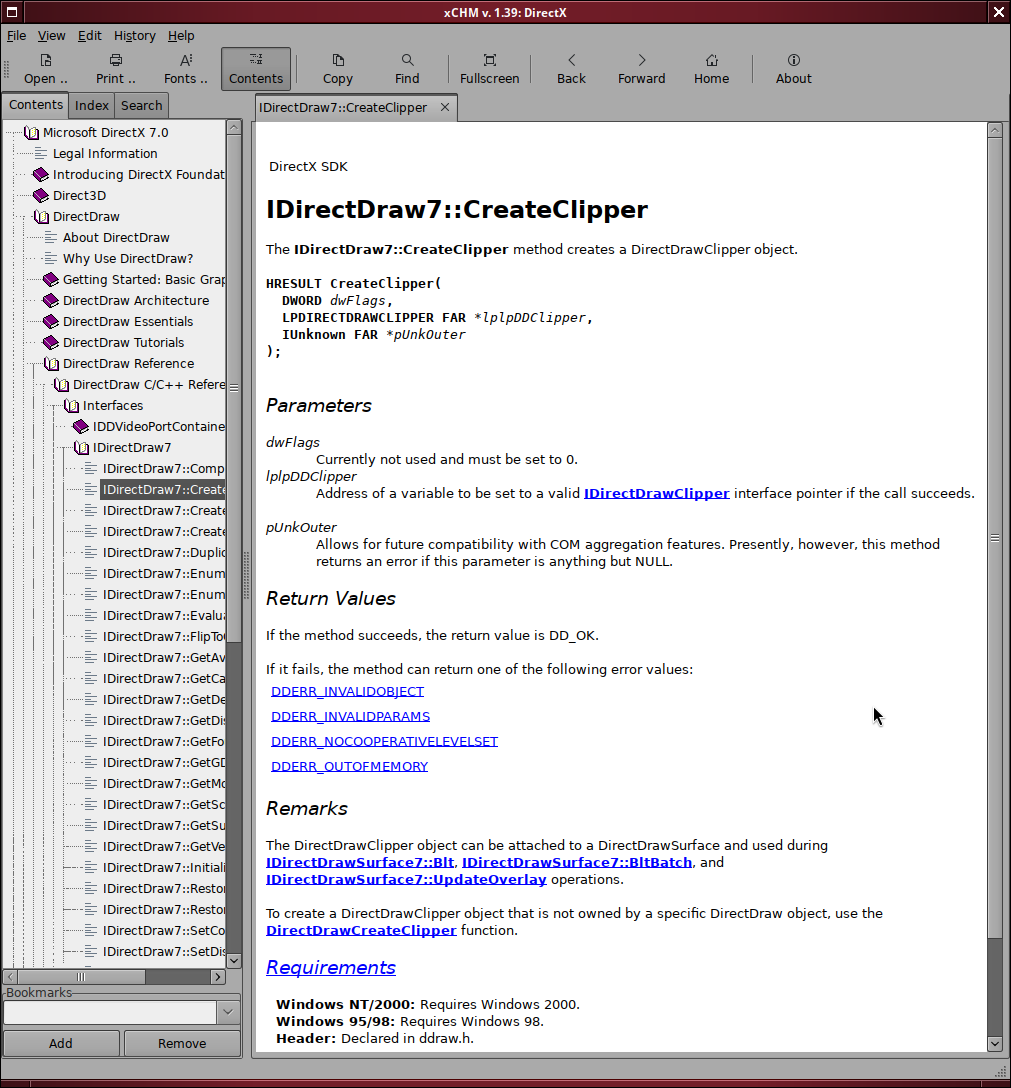
As an example i asked Devstral Small 2 to write some docs for my LIL scripting language in the following style (this is copied from the DirectDraw documentation, edited to be text friendly):
IDirectDraw7::CreateClipper
---------------------------
The IDirectDraw7::CreateClipper method creates a DirectDrawClipper object.
HRESULT CreateClipper(
DWORD dwFlags,
LPDIRECTDRAWCLIPPER FAR *lplpDDClipper,
IUnknown FAR *pUnkOuter
);
Parameters
* dwFlags - Currently not used and must be set to 0.
* lplpDDClipper - Address of a variable to be set to a valid
IDirectDrawClipper interface pointer if the call succeeds.
* pUnkOuter - Allows for future compatibility with COM aggregation features.
Presently, however, this method returns an error if this parameter is
anything but NULL.
Return Values
If the method succeeds, the return value is DD_OK.
If it fails, the method can return one of the following error values:
* DDERR_INVALIDOBJECT
* DDERR_INVALIDPARAMS
* DDERR_NOCOOPERATIVELEVELSET
* DDERR_OUTOFMEMORY
Remarks
The DirectDrawClipper object can be attached to a DirectDrawSurface and used
during IDirectDrawSurface7::Blt, IDirectDrawSurface7::BltBatch, and
IDirectDrawSurface7::UpdateOverlay operations.
To create a DirectDrawClipper object that is not owned by a specific
DirectDraw object, use the DirectDrawCreateClipper function.
Requirements
Windows NT/2000: Requires Windows 2000.
Windows 95/98: Requires Windows 98.
Header: Declared in ddraw.h.
See Also
IDirectDrawSurface7::GetClipper, IDirectDrawSurface7::SetClipper
[0] https://app.filen.io/#/d/9f4c1225-3527-4f16-a522-0678342120c...
[1] http://runtimeterror.com/pages/iv/images/45f8df428afe4fe6b6a...
{kind=link}
[2] http://runtimeterror.com/pages/iv/images/ee58032790a049d7e74...
{kind=link}
Comment by theletterf 4 days ago
Comment by badsectoracula 4 days ago
Unfortunately i only have a 24GB GPU - and an AMD one at that - so there isn't much i can do on that front. Supposedly a 24GB GPU is enough for finetuning a 24B model with 4bit QLoRA, though when i tried it with some finetuning app (in an official docker container) it barfed at Mistral's weird template or something and i lost interest after that.
Comment by theletterf 4 days ago
Comment by badsectoracula 4 days ago
Comment by zahlman 4 days ago
In your experience, is it worthwhile to have an agent create a "skill" for itself for following the style? Or is it a better use of context to just have it review the examples?
Comment by badsectoracula 3 days ago
Out of curiosity i just tried having the LLM generate a document describing the style, then (after a memory reset) i asked it to use the document and it did more or less the same job, however the document also had an example and the example seemed to do most of the "real job" of describing the style because at first the function docs that were generated were prefixed with 4 spaces - like the example in the doc (but the example in the doc had four spaces for indentation) and after i edited the doc to remove the spaces the function docs it generated were like those generated in the transcript i linked above.
Which makes me think that the example is the better approach (since the doc also had an example) and perhaps the best is to give an example with clarifications about the parts the example doesn't cover (like using a 80 line character limit).
FWIW when i wanted the LLM to write some new C source + header files some time ago, i also pointed it to an existing pair of C/H files to use for the code style and it worked fine, so at least in my experience examples seem to work very good.
Comment by selfhoster1312 4 days ago
Comment by spacebacon 5 days ago
https://github.com/space-bacon/SRT
The HF zool4nd3r demo may be useful
Comment by janalsncm 5 days ago
Also your documents use a ton of nonstandard jargon which only serve to confuse laypeople and annoy anyone who is familiar with ML. Saying your change adds “semiotic awareness” is meaningless when your experiments claim only marginal improvements. Clearly the model had most of the capability before.
More generally, who is it for? People who have expertise in ML are not going to take it seriously. People who don’t?
Comment by spacebacon 5 days ago
The layers 7, 14, and 21 were chosen after probing. They showed the strongest regime signals. We did compare other layers. The term semiotic awareness is just shorthand for detecting and modulating higher order meaning patterns. If the term is unhelpful I will drop it.
The capability gains are often marginal on standard benchmarks. The intended value is observability and steerability without retraining the backbone.
Comment by anentropic 5 days ago
Comment by janalsncm 5 days ago
Also to say that a philosopher that died 100 years ago inspired a new attention head is another instance of GPT off his rocker again. You don’t need MAH to contextualize “freedom” in a sentence. Attention already does that.
Comment by spacebacon 5 days ago
Edit: its not GPT nor off rocker. This repo empirically proved computational semiotics with the reference to C.S. Peirce, Paul Kockelman, and many other respected contemporary semioticians.
Comment by anentropic 5 days ago
The technical implementation details are also useful to have, but they're a bit hard to parse into "what is this?"
Comment by anentropic 5 days ago
they need specific coaching to get them to try to write for the perspective of a new user
Comment by spacebacon 4 days ago
Comment by anentropic 4 days ago
Comment by spacebacon 3 days ago
Comment by spacebacon 5 days ago
Comment by janalsncm 5 days ago
Comment by spacebacon 4 days ago
Comment by nextaccountic 5 days ago
Also is SRT really suitable for style transfer?
I mean this seems to be another network overlaid on top of the LLM steering it, but it needs some target to determine whether the underlying LLM drifted away from it
Comment by spacebacon 5 days ago
It is an overlay, but it works by modulating meaning level patterns called regimes rather than fixed steering vectors. Because it can read its own effect on the hidden states it gives a way to observe whether output is staying in the target regime or drifting.
It is not raw data in and raw style out. The adapter needs examples that define the desired regime.
Comment by sspoisk 4 days ago
Comment by realfutureman 5 days ago
Comment by openclawclub 4 days ago
Comment by DuduZhvania 4 days ago
Comment by m_m_carvalho 4 days ago
Comment by openclawclub 4 days ago
Comment by eddysir 4 days ago
Comment by krupan 4 days ago