Claude Opus 4.7 costs 20–30% more per session
Posted by aray07 4 hours ago
Comments
Comment by louiereederson 4 hours ago
To me, it is hard to reject this hypothesis today. The fact that Anthropic is rapidly trying to increase price may betray the fact that their recent lead is at the cost of dramatically higher operating costs. Their gross margins in this past quarter will be an important data point on this.
I think the tendency for graphs of model assessment to display the log of cost/tokens on the x axis (i.e. Artificial Analysis' site) has obscured this dynamic.
Comment by louiereederson 3 hours ago
Comment by fragmede 1 hour ago
Comment by piker 54 minutes ago
Comment by louiereederson 54 minutes ago
I'd also flip your framing on its head. One of the advantages of human labor over agents is accountability. Someone needs to own the work at the end of the day, and the incentive alignment is stronger for humans given that there is a real cost to being fired.
Comment by kennywinker 17 minutes ago
Comment by pona-a 56 minutes ago
Comment by krainboltgreene 19 minutes ago
Comment by Aurornis 2 hours ago
I think we're reaching the point where more developers need to start right-sizing the model and effort level to the task. It was easy to get comfortable with using the best model at the highest setting for everything for a while, but as the models continue to scale and reasoning token budgets grow, that's no longer a safe default unless you have unlimited budgets.
I welcome the idea of having multiple points on this curve that I can choose from. depending on the task. I'd welcome an option to have an even larger model that I could pull out for complex and important tasks, even if I had to let it run for 60 minutes in the background and made my entire 5-hour token quota disappear in one question.
I know not everyone wants this mental overhead, though. I predict we'll see more attempts at smart routing to different models depending on the task, along with the predictable complaints from everyone when the results are less than predictable.
Comment by KronisLV 5 minutes ago
For a while I used Cerebras Code for 50 USD a month with them running a GLM model and giving you millions of tokens per day. It did a lot of heavy lifting in a software migration I was doing at the time (and made it DOABLE in the first place), BUT there were about 10 different places where the migration got fucked up and had to manually be fixed - files left over after refactoring (what's worse, duplicated ones basically), some constants and routes that are dead code, some development pages that weren't removed when they were superseded by others and so on.
I would say that Claude Code with throwing Opus at most problems (and it using Sonnet or Haiku for sub-agents for simple and well specified tasks) is actually way better, simply because it fucks things up less often and review iterations at least catch when things are going wrong like that. Worse models (and pretty much every one that I can afford to launch locally, even ones that need around ~80 GB of VRAM in the context of an org wanting to self-host stuff) will be confidently wrong and place time bombs in your codebases that you won't even be aware of if you don't pay enough attention to everything - even when the task was rote bullshit that any model worth its salt should have resolved with 0 issues.
Comment by dahart 10 minutes ago
I’m curious how to even do it. I have no idea how to choose which model to use in advance of a given task, regardless of the mental overhead.
And unless you can predict perfectly what you need, there’s going to be some overuse due to choosing the wrong model and having to redo some work with a better model, I assume?
Comment by dustingetz 51 minutes ago
Comment by Leynos 57 minutes ago
Comment by jpalawaga 1 hour ago
Comment by justapassenger 50 minutes ago
That's how things worked pre-AI, and old problems are new problems again.
When you run any bigger project, you have senior folks who tackle hardest parts of it, experienced folks who can churn out massive amounts of code, junior folks who target smaller/simpler/better scoped problems, etc.
We don't default to tell the most senior engineer "you solve all of those problems". But they're often involved in evaluation/scoping down/breakdown of problem/supervising/correcting/etc.
There's tons of analogies and decades of industry experience to apply here.
Comment by nilkn 1 hour ago
Comment by KaiShips 1 hour ago
Comment by snek_case 3 hours ago
So there's a push for them to increase revenue per user, which brings us closer to the real cost of running these models.
Comment by giwook 3 hours ago
At that point you are beholden to your shareholders and no longer can eschew profit in favor of ethics.
Unfortunately, I think this is the beginning of the end of Anthropic and Modei being a company and CEO you could actually get behind and believe that they were trying to do "the right thing".
It will become an increasingly more cutthroat competition between Anthropic and OpenAI (and perhaps Google eventually if they can close the gap between their frontier models and Claude/GPT) to win market share and revenue.
Perhaps Amodei will eventually leave Anthropic too and start yet another AI startup because of Anthropic's seemingly inevitable prioritization of profit over safety.
Comment by snek_case 3 hours ago
Comment by bombcar 2 hours ago
Just how if Boeing was able to release a supersonic plane that was also twice as efficient tomorrow; it'd destroy any airline that was deep in debt for its current "now worthless" planes.
Comment by outofpaper 1 hour ago
Comment by devmor 3 hours ago
A publicly traded company is legally obligated to go against the global good.
Comment by mattkevan 3 hours ago
Comment by dboreham 2 hours ago
Comment by chrisweekly 7 minutes ago
Comment by tehjoker 17 minutes ago
Comment by renticulous 1 hour ago
Comment by WarmWash 3 hours ago
So no matter what, if you do something lots of people like (and hence compensate you for), you will be evil.
It's a very interesting quirk of human intuition.
Comment by arcanemachiner 3 hours ago
Can't blame someone who comes to such a conclusion about money and power.
Comment by WarmWash 1 hour ago
Comment by epsilonic 1 hour ago
Comment by ModernMech 1 hour ago
Comment by WarmWash 49 minutes ago
Yet here they are, often considered on of the most evil companies on Earth. That's the interesting quirk.
Comment by ModernMech 44 minutes ago
Comment by devmor 13 minutes ago
Can you explain what you mean by this? I disagree but I don't understand how you think Google did this so I am very curious.
For my part, I started using the internet before Google, and I strongly hold the opinion that Google's greatest contribution to the internet was utterly destroying its peer to peer, free, open exchange model by being the largest proponent of centralizing and corporatizing the web.
Comment by tehjoker 15 minutes ago
Comment by giwook 3 hours ago
Call me an optimist, but I'm still holding out hope that Amodei is and still can do the right thing. That hope is fading fast though.
Comment by ljm 2 hours ago
I was about to call it reselling but so many startups with their fingers in the tech startup pie offer containerised cloud compute akin to a loss leader. Harking back to the old days of buying clock time on a mainframe except you're getting it for free for a while.
Comment by zozbot234 2 hours ago
Comment by Lihh27 18 minutes ago
Comment by ethin 2 hours ago
Comment by ezst 1 hour ago
I'd rather be surprised if they are still doing business by then.
Comment by QuiEgo 1 hour ago
I’m guessing we’re gonna have a world like working on cars - most people won’t have expensive tools (ex a full hydraulic lift) for personal stuff, they are gonna have to make do with lesser tools.
Comment by cyanydeez 16 minutes ago
i bought a $3k AMD395+ under the Sam Altman price hike and its got a local model that readily accomplishes medial tasks.
theres a ceiling to these price hikes because open weights will keep popping up as competitors tey to advertise their wares.
sure, we POV different capabilities but theres definitely not that much cash in propfietary models for their indererminance
Comment by paulddraper 3 hours ago
Or they are just not willing to burn obscene levels of capital like OpenAI.
Comment by _pdp_ 3 hours ago
It is like comparing an 8K display to a 16K display because at normal viewing distance, the difference is imperceptible, but 16K comes at significant premium.
The same applies to intelligence. Sure, some users might register a meaningful bump, but if 99% can't tell the difference in their day-to-day work, does it matter?
A 20-30% cost increase needs to deliver a proportional leap in perceivable value.
Comment by highfrequency 1 hour ago
This is also why I don't see the models getting commoditized anytime soon - the dimensionality of LLM output that is economically relevant keeps growing linearly for coding (therefore the possibility space of LLM outputs grows exponentially) which keeps the frontier nontrivial and thus not commoditized.
In contrast, there is not much demand for 100 page articles written by LLMs in response to basic conversational questions, therefore the models are basically commoditized at answering conversational questions because they have already saturated the difficulty/usefulness curve.
Comment by ZeroCool2u 3 hours ago
Comment by UncleOxidant 3 hours ago
Comment by Aurornis 2 hours ago
Comment by blurbleblurble 2 hours ago
Lately I've been wondering too just how large these proprietary "ultra powerful frontier models" really are. It wouldn't shock me if the default models aren't actually just some kind of crazy MoE thing with only a very small number of active params but a huge pool of experts to draw from for world knowledge.
Comment by manmal 1 hour ago
Comment by robot_jesus 3 hours ago
If I can get the performance I'm seeing out of free models on a 6-year-old Macbook Pro M1, it's a sign of things to come.
Frontier models will have their place for 1) extensive integrations and tooling and 2) massive context windows. But I could see a very real local-first near future where a good portion of compute and inference is run locally and only goes to a frontier model as needed.
Comment by UncleOxidant 3 hours ago
Comment by efficax 2 hours ago
Comment by snek_case 3 hours ago
For coding though, there is kind of no limit to the complexity of software. The more invariants and potential interactions the model can be aware of, the better presumably. It can handle larger codebases. Probably past the point where humans could work on said codebases unassisted (which brings other potential problems).
Comment by levocardia 2 hours ago
Comment by 9dev 2 hours ago
Comment by altern8 1 hour ago
If Claude understood what you mean better without you having to over explain it would be an improvement
Comment by simplyluke 2 hours ago
Comment by mlinsey 3 hours ago
Comment by manmal 1 hour ago
Comment by aray07 3 hours ago
Comment by margorczynski 2 hours ago
It doesn't matter if a model is e.g. 30% cheaper to use than another (token-wise) but I need to burn 2x more tokens to get the same acceptable result.
Comment by Bridged7756 1 hour ago
You raised a good point, what's a good metric for LLM performance? There's surely all the benchmarks out there, but aren't they one and done? Usually at release? What keeps checking the performance of those models. At this point it's just by feel. People say models have been dumbed down, and that's it.
I think the actual future is open source models. Problem is, they don't have the huge marketing budget Anthropic or OpenAI does.
Comment by _pdp_ 2 hours ago
Comment by mgraczyk 1 hour ago
Comment by nisegami 3 hours ago
It's not necessary a single discrete point I think. In my experience, it's tied to the quality/power of your harness and tooling. More powerful tooling has made revealed differences between models that were previously not easy to notice. This matches your display analogy, because I'm essentially saying that the point at which display resolution improvements are imperceptible matters on how far you sit.
Comment by wellthisisgreat 2 hours ago
I was always wondering where that breaking point for cost/peformance is for displays. I use 4K 27” and it’s noticeably much better for text than 1440p@27 but no idea if the next/ and final stop is 6k or 8k?
Comment by zozbot234 1 hour ago
Comment by solenoid0937 26 minutes ago
I switched to the Studio Display XDR and it is noticeably better than my 4k displays and my 1440p displays feel positively ancient and near unusable for text.
Comment by iLoveOncall 2 hours ago
You mean a couple of years ago?
Comment by speedgoose 2 hours ago
https://docs.github.com/fr/copilot/reference/ai-models/suppo...
Comment by Someone1234 2 hours ago
At 7.5x for 4.7, heck no. It isn't even clear it is an upgrade over Opus 4.6.
Comment by chewz 19 minutes ago
Opus 4.5 and 4.6 will be removed very soon.
So what is your contingency plan?
Comment by GaryBluto 1 hour ago
Comment by solenoid0937 25 minutes ago
Comment by bwat49 2 hours ago
Comment by admiralrohan 31 minutes ago
Human psychology is surprisingly similar, and same pattern comes across domains.
Comment by hirako2000 23 minutes ago
I didn't buy Springles chips in years, even the box now is nothing like it was. Thinner. Shorter. I imagine how far from the top the slices stack up.
Comment by steelbrain 17 minutes ago
Comment by namnnumbr 3 hours ago
The final calculation assumes that Opus 4.7 uses the exact same trajectory + reasoning output as Opus 4.6. I have not verified, but I assume it not to be the case, given that Opus 4.7 on Low thinking is strictly better than Opus 4.6 on Medium, etc., etc.
Comment by bisonbear 2 hours ago
Comment by cced 1 hour ago
Progress. /s
Comment by bisonbear 1 hour ago
> Progress. /s
pretty much, lmao. my theory is 4.6 started thinking less to save compute for 4.7 release. but who knows what's going on at anthropic
Comment by kirubakaran 53 minutes ago
People at Anthropic
Comment by namnnumbr 46 minutes ago
https://www.anthropic.com/_next/image?url=https%3A%2F%2Fwww-...
{kind=link}
Comment by aray07 3 hours ago
"given that Opus 4.7 on Low thinking is strictly better than Opus 4.6 on Medium, etc., etc.”
Opus 4.7 in general is more expensive for similar usage. Now we can argue that is provides better performance all else being equal but I haven’t been able to see that
Comment by unpwn 3 hours ago
Comment by namnnumbr 42 minutes ago
1. In my own use, since 1 Apr this month, very heavy coding:
> 472.8K Input Tokens +299.3M cached > 2.2M Output Tokens
My workloads generate ~5x more output than input, and output tokens cost 5x more per token... output dominates my bill at roughly 25x the cost of input. (Even more so when you consider cache hits!) If Opus 4.7 was more efficient with reasoning (and thus output), I'd likely save considerable money (were I paying per-token).
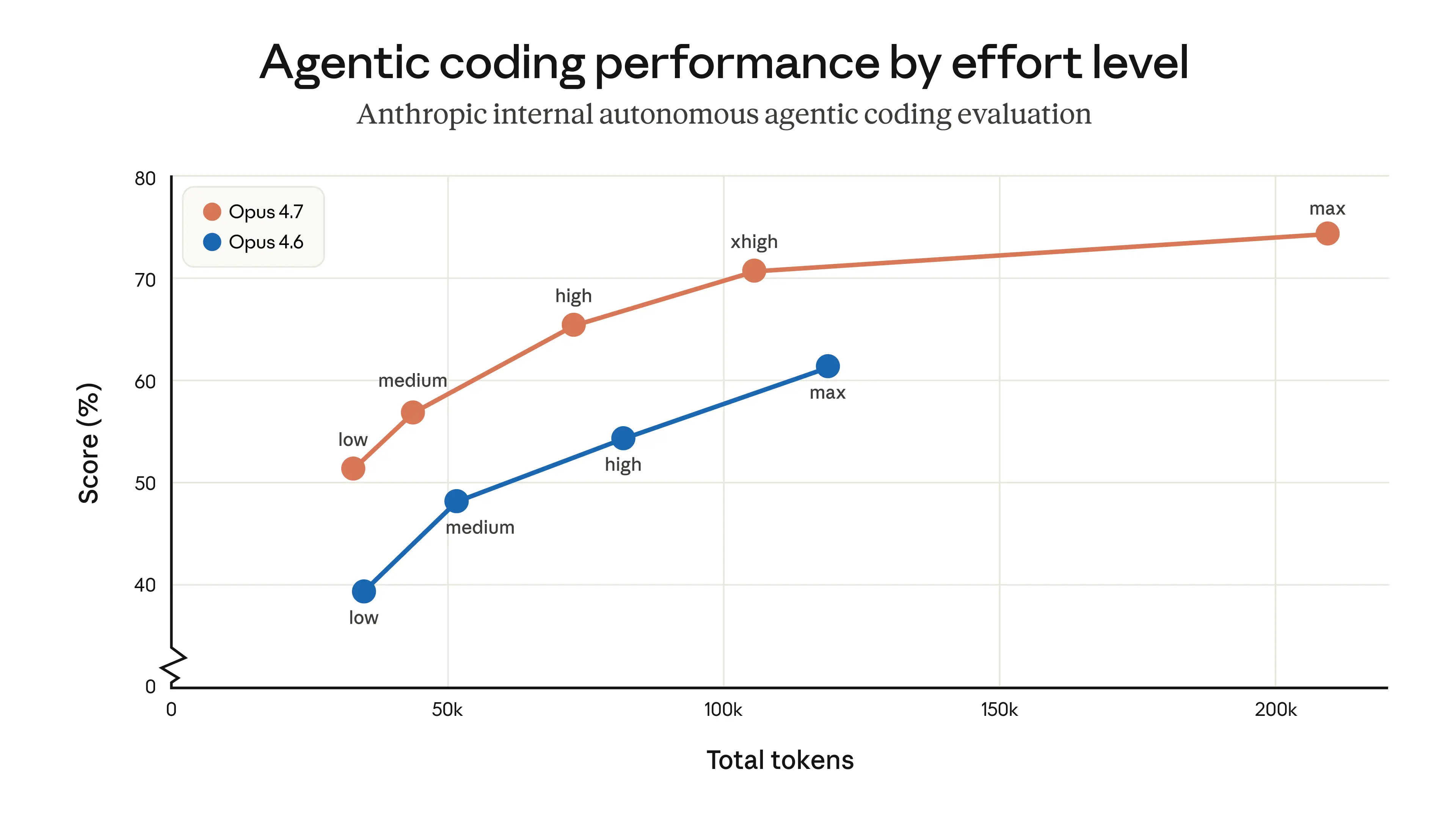
2. Anthropic's benchmarks DO show strictly-better (granted they are Anthropic's benchmarks, so salt may be needed) https://www.anthropic.com/_next/image?url=https%3A%2F%2Fwww-...
Comment by watsonL1F7 3 hours ago
Comment by montjoy 2 hours ago
> max: Max effort can deliver performance gains in some use cases, but may show diminishing returns from increased token usage. This setting can also sometimes be prone to overthinking. We recommend testing max effort for intelligence-demanding tasks.
> xhigh (new): Extra high effort is the best setting for most coding and agentic use cases
Ref: https://platform.claude.com/docs/en/build-with-claude/prompt...
Comment by dcrazy 2 hours ago
Comment by _fat_santa 3 hours ago
I think a big issue with the industry right now is it's constantly chasing higher performing models and that comes at the cost of everything else. What I would love to see in the next few years is all these frontier AI labs go from just trying to create the most powerful model at any cost to actually making the whole thing sustainable and focusing on efficiency.
The GPT-3 era was a taste of what the future could hold but those models were toys compare to what we have today. We saw real gains during the GPT-4 / Claude 3 era where they could start being used as tools but required quite a bit of oversight. Now in the GPT-5 / Claude 4 era I don't really think we need to go much further and start focusing on efficiency and sustainability.
What I would love the industry to start focusing on in the next few years is not on the high end but the low end. Focus on making the 0.5B - 1B parameter models better for specific tasks. I'm currently experimenting with fine-tuning 0.5B models for very specific tasks and long term I think that's the future of AI.
Comment by namnnumbr 34 minutes ago
If you can forgive the obviously-AI-generated writing, [CPUs Aren't Dead](https://seqpu.com/CPUsArentDead) makes an interesting point on AI progress: Google's latest, smallest Gemma model (Gemma 4 E2B), which can run on a cell phone, outperforms GPT-3.5-turbo. Granted, this factoid is based on `MT-Bench` performance, a benchmark from 2023 which I assume to be both fully saturated and leaked into the training data for modern LLMs. However, cross-referencing [Artificial Analysis' Intelligence Index](https://artificialanalysis.ai/models?models=gemma-4-e2b-non-...) suggests that indeed the latest 2B open-weights models are capable of matching or beating 175B models from 3-4 years ago. Perhaps more impressive, [Gemma 4 E4B matches or beats GPT-4o](https://artificialanalysis.ai/models?models=gemma-4-e4b%2Cge...) on many benchmarks.
If this trend continues, perhaps we'll have the capabilities of today's best models available to reasonably run on our laptops!
Comment by Bridged7756 1 hour ago
I personally think the whole "the newest model is crazy! You've gotta use X (insert most expensive model)" Is just FOMO and marketing-prone people just parroting whatever they've seen in the news or online.
Comment by minimaxir 2 hours ago
Comment by malfist 19 minutes ago
I'm not seeing that in my testing, but these opinions are all vibe based anyway.
Comment by renticulous 1 hour ago
Comment by fkealy 2 hours ago
Comment by rambojohnson 1 hour ago
Comment by atonse 4 hours ago
I'm already at 27% of my weekly limit in ONE DAY.
Comment by jabart 3 hours ago
Comment by cbm-vic-20 3 hours ago
Comment by aray07 3 hours ago
it seems to hallucinate a bit more (anecdotal)
Comment by titaniumtown 3 hours ago
Comment by dminik 2 hours ago
Brilliant.
Comment by CharlesW 2 hours ago
Ouch, that's very different than experience. What effort level? Are you careful to avoid pushing session context use beyond 350k or so (assuming 1m context)?
Comment by atonse 1 hour ago
And this particular set of things has context routinely hit 350-450k before I compact.
That's likely what it is? I think this particular work stream is eating a lot of tokens.
Earlier this week (before Open 4.7 hit), I just turned off 1m context and had it grow a lot slower.
I also have it on high all the time. Medium was starting to feel like it was making the occasional bad decisions and also forgetting things more.
Comment by JimmaDaRustla 1 hour ago
Comment by AndyNemmity 1 hour ago
All of us doing crazy agentic stuff were fine on max before this. Now with Opus 4.7, we're no longer fine, and troubleshooting, and working through options.
Comment by JimmaDaRustla 1 hour ago
Ya...you may be who I'm talking about though (if you're speaking from experience). If your methodology is "I used 4.6 max, so I'm going to try 4.7 max" this is fully on you - 4.7 max is not equivalent to 4.6 max, you want 4.7 xhigh.
From their docs:
max: Max effort can deliver performance gains in some use cases, but may show diminishing returns from increased token usage. This setting can also sometimes be prone to overthinking. We recommend testing max effort for intelligence-demanding tasks.
xhigh (new): Extra high effort is the best setting for most coding and agentic use cases.
Comment by AndyNemmity 1 hour ago
I am on xhigh.
Comment by JimmaDaRustla 48 minutes ago
I've always used high, so maybe I should be using xhigh
Comment by AndyNemmity 18 minutes ago
I used up 1/3rd of my context in less than a day. I am working diligently to do whatever I can to lower token usage.
Comment by sreekanth850 2 hours ago
Comment by AndyNemmity 1 hour ago
Comment by epistasis 14 minutes ago
So far it costs a lot less, because I'm not going to be using it.
Comment by mrtesthah 11 minutes ago
Comment by sipsi 3 hours ago
Comment by jstummbillig 40 minutes ago
This is not so much about my instructions being followed more closely. It's the LLM being smarter about what's going on and for example saving me time on unnecessary expeditions. This is where models have been most notably been getting better to my experience. Understanding the bigger picture. Applying taste.
It's harder to measure, of course, but, at least for my coding needs, there is still a lot of room here.
If one session costs an additional 20% that's completely fine, if that session gets me 20% closer to a finished product (or: not 20% further away). Even 10% closer would probably still be entirely fine, given how cheap it is.
Comment by uberman 4 hours ago
Given that Opus 4.6 and even Sonnet 4.6 are still valid options, for me the question is not "Does 4.7 cost more than claimed?" but "What capabilities does 4.7 give me that 4.6 did not?"
Yesterday 4.6 was a great option and it is too soon for me to tell if 4.7 is a meaningful lift. If it is, then I can evaluate if the increased cost is justified.
Comment by tetha 2 hours ago
I'll look at the new models, but increasing the token consumptions by a factor of 7 on copilot, and then running into all of these budget management topics people talk about? That seems to introduce even more flow-breakers into my workflow, and I don't think it'll be 7 times better. Maybe in some planning and architectural topics where I used Opus 4.6 before.
Comment by pier25 4 hours ago
Comment by solenoid0937 4 hours ago
https://marginlab.ai/trackers/claude-code-historical-perform...
Comment by addisonj 3 hours ago
But... Are you really going to completely rely on benchmarks that have time and time again be shown to be gamed as the complete story?
My take: It is pretty clear that the capacity crunch is real and the changes they made to effort are in part to reduce that. It likely changed the experience for users.
Comment by Majromax 4 hours ago
Moreover, on the companion codex graphs (https://marginlab.ai/trackers/codex-historical-performance/), you can see a few different GPT model releases marked yet none correspond to a visual break in the series. Either GPT 5.4-xhigh is no more powerful than GPT 5.2, or the benchmarking apparatus is not sensitive enough to detect such changes.
Comment by yorwba 1 hour ago
Comment by cbg0 4 hours ago
Comment by solenoid0937 2 hours ago
Comment by cbg0 1 hour ago
Comment by ed_elliott_asc 4 hours ago
Comment by grim_io 4 hours ago
Comment by Jeremy1026 4 hours ago
Comment by hypercube33 3 hours ago
Comment by nfredericks 4 hours ago
Comment by grim_io 3 hours ago
Comment by margorczynski 2 hours ago
Looks like they lost the mandate of heaven, if Open AI plays it right it might be their end. Add to that the open source models from China.
Comment by solenoid0937 20 minutes ago
2. Anthropic and OpenAI's financials are totally different. The former has nearly the same RRR and a fraction of the cash burn. There is a reason Anthropic is hot on secondary and OAI isn't
Comment by throwaway041207 1 hour ago
When I read these comments on Hacker News, I see a lot of people miffed about their personal subscription limits. I think this is a viewpoint that is very consumer focused, and probably within Anthropic they're seeing buckets of money being dumped on them from enterprises. They probably don't really care as much about the individual subscription user, especially power users.
Comment by therobots927 2 hours ago
Comment by chakintosh 9 minutes ago
Comment by jmward01 3 hours ago
Recently it started promoting me for feedback even though I am on API access and have disabled this. When I did a deep dive of their feedback mechanism in the past (months ago so probably changed a lot since then) the feedback prompt was pushing message ids even if you didn't respond. If you are on API usage and have told them no to training on your data then anything pushing a message id implies that it is leaking information about your session. It is hard to keep auditing them when they push so many changes so I am now 'default they are stealing my info' instead of believing their privacy/data use policy claims. Basically, my level of trust is eroding fast in their commitment to not training on me and I am paying a premium to not have that happen.
Comment by motbus3 33 minutes ago
4.6 performers worse or the same in most of the tasks I have. If there is a parameter that made me use 4.6 more frequently is because 4.5 get dumber and not because 4.6 seemed smarter.
Comment by qq66 3 hours ago
Comment by Bridged7756 1 hour ago
Comment by technotony 3 hours ago
Comment by mfro 2 hours ago
Comment by taosx 3 hours ago
Comment by QuercusMax 2 hours ago
You're offended by their political beliefs, so you don't like the way the model works?
Comment by estearum 3 hours ago
Comment by testbjjl 3 hours ago
I also wonder if token utilization has or will ever find its way to employee performance reviews as these models go up in price.
Comment by jmward01 4 hours ago
Comment by aray07 3 hours ago
Comment by jmward01 34 minutes ago
People that think they got what they wanted, the feature is there!, so they can't complain but...
People that end up essentially randomly picking so the average value of the choices made by customers is suboptimal.
Comment by jddj 3 hours ago
Comment by JimmaDaRustla 1 hour ago
Comment by Yukonv 3 hours ago
Comment by avereveard 1 hour ago
Comment by iknowstuff 4 hours ago
Comment by aray07 3 hours ago
Comment by QuercusMax 2 hours ago
And then it proceeded to rewrite the block with a dict lookup plus if-elses, instead of using match/case. I had to nag it to actually rewrite the code the way it said it would!
Comment by yuanzhi1203 2 hours ago
https://matrix.dev/blog-2026-04-16.html (We were talking to Opus 4.7 twelve days ago)
Comment by wartywhoa23 45 minutes ago
Comment by adaptive_loop 3 hours ago
Comment by bityard 2 hours ago
I am finding that for complex tasks, Claude's quality of output varies _tremendously_ with repeated runs of the same model and prompt. For example, last week I wrote up (with my own brain and keyboard) a somewhat detailed plain english spec of a work-related productivity app that I've always wanted but never had the time to write. It was roughly the length of an average college essay. The first thing I asked Claude to do was not write any code, but come up with a more formal design and implementation plan based on the requirements that I gave. The idea was to then hand _that_ to Claude and say, okay, now build it.
I used Opus 4.6 with High reasoning for all of this and did not change any model settings between runs.
The first run was overall _amazing_. It was detailed, well-written, contained everything that I asked for. The only drawback was that I was ambiguous on a couple of points which meant that the model went off and designed something in a way that I wasn't expecting and didn't intend. So I cleared that up in my prompt, and instead of keeping the context and building on what was already there, I started a new chat and had it start again from scratch.
What it wrote the second time was _far_ less impressive. The writing was terse, there was a lot less detail, the pretty dependency charts and various tables it made the first time were all gone. Lots of stuff was underspecified or outright missing.
New chat, start again. Similar results as the second run, maybe a bit worse. It also started _writing code_ which was something I told it NOT to do. At this point I'm starting to panic a little because I'm sure I didn't add, "oh, and make it crappy" to the prompt and I was a little angry about not saving the first iteration since it was fairly close to what I had wanted anyway.
I decided to try one last time and it finally gave me back something within about 95% of the first run in terms of quality, but with all the problems fixed. So, I was (finally) happy with that, and it used that to generate the application surprisingly well, with only a few issues that should not be too hard to fix after the fact.
So I guess 4th time was a charm, and the fare was about $7 in tokens to get there.
Comment by therobots927 3 hours ago
Comment by outlore 31 minutes ago
Comment by sysmax 3 hours ago
Except, it's not that trivial to solve. I tried experimenting with asking the model to first give a list of symbols it will modify, and then just write the modified symbols. The results were OK, but less refined than when it echoes back the entire file.
The way I see it is that when you echo back the entire file, the process of thinking "should I do an edit here" is distributed over a longer span, so it has more room to make a good decision. Like instead of asking "which 2 of the 10 functions should you change" you're asking it "should you change method1? what about method2? what about method3?", etc., and that puts less pressure on the LLM.
Except, currently we are effectively paying for the LLM to make that decision for *every token*, which is terribly inefficient. So, there has to be some middle ground between expensively echoing back thousands of unchanged tokens and giving an error-ridden high-level summary. We just haven't found that middle ground yet.
Comment by mmastrac 3 hours ago
grit.io was working on this years ago, not sure if they are still alive/around, but I liked their approach (just had a very buggy transformer/language).
Comment by gruez 3 hours ago
I thought coding harnesses provided tools to apply diffs so the LLM didn't have to echo back the entire file?
Comment by sysmax 3 hours ago
So, in practice, many tools still work on the file level.
Comment by khalic 2 hours ago
Comment by beej71 3 hours ago
And if it's not good enough for coding, what kind of money, if any, would make it good enough?
Comment by arcanemachiner 3 hours ago
Do yourself a favor: Set up OpenCode and OpenRouter, and try all the models you want to try there.
Other than the top performers (e.g. GLM 5.1, Kimi K2.5, where required hardware is basically unaffordable for a single person), the open models are more trouble than they're worth IMO, at least for now (in terms of actually Getting Shit Done).
Comment by _345 2 hours ago
Comment by zozbot234 1 hour ago
Open models are not bullshit, they work fine for many cases and newer techniques like SSD offload make even 500B+ models accessible for simple uses (NOT real-time agentic coding!) on very limited hardware. Of course if you want the full-featured experience it's going to cost a lot.
Comment by solenoid0937 17 minutes ago
People that love open models dramatically overstate how good the benchmaxxed open models are. They are nowhere near Opus.
Comment by __mharrison__ 1 hour ago
I took the plan that I used from Codex and handed it to opencode with Qwen 3.5 running locally.
It created a library very similar to Codex but took 2x longer.
I haven't tried Qwen 3.6 but I hear it's another improvement. I'm confident with my AI skills that if/when cheap/subsidized models go away, I'll be fine running locally.
Comment by mfro 2 hours ago
Fun fact: AWS offers apple silicon EC2 instances you can spin up to test.
Comment by hleszek 3 hours ago
Comment by bakugo 3 hours ago
Many providers out there host open weights models for cheap, try them out and see what you think before actually investing in hardware to run your own.
Comment by aray07 3 hours ago
Comment by DeathArrow 2 hours ago
The best bang for the buck now is subcribing to token plans from Z.ai (GLM 5.1), MiniMax (MiniMax M2.7) or ALibaba Cloud (Qwen 3.6 Plus)
Running quantized models won't give you results comparable to Opus or GPT.
Comment by ndom91 2 hours ago
Comment by redml 2 hours ago
Comment by DiscourseFan 2 hours ago
Comment by rafram 3 hours ago
Comment by AIrtemis 37 minutes ago
Comment by lacoolj 3 hours ago
> In Claude Code, we’ve raised the default effort level to xhigh for all plans.
Try changing your effort level and see what results you get
Comment by aray07 3 hours ago
I find 5 thinking levels to be super confusing - I dont really get why they went from 3 -> 5
Comment by aliljet 3 hours ago
Comment by cbg0 1 hour ago
Comment by aray07 3 hours ago
Comment by AndyNemmity 1 hour ago
So yes, for the same tasks, usage runs out faster (currently)
Comment by curioussquirrel 3 hours ago
Comment by arcanemachiner 3 hours ago
Comment by curioussquirrel 27 minutes ago
Comment by markrogersjr 3 hours ago
Comment by ChicagoBoy11 3 hours ago
Comment by markrogersjr 2 hours ago
Comment by rambojohnson 2 hours ago
And now maintaining that pace means absorbing arbitrary price increases, shrugged off with “we were operating at a loss anyway.”
It stops being “pay to play” and starts looking more like pay just to stay in the ring, while enterprise players barely feel the hit and everyone else gets squeezed out.
Market maturing my butthole... it’s obviously a dependency being priced in real time. Tech is an utter shit show right now, compounded by the disaster of the unemployment market still reeling from the overhiring of 2020.
save up now and career pivot. pick up gardening.
Comment by wslh 2 hours ago
"Utility" is close, but "energy source" may be closer. When it becomes the thing powering the pace of work itself, raising prices is less about charging for access and more about taxing dependency.
Comment by colechristensen 2 hours ago
Comment by wslh 2 hours ago
Comment by colechristensen 1 hour ago
Comment by wslh 1 hour ago
In this context I also imagine we will have greater and greater local models, and the (dependency) ending game is completely unclear.
Comment by AIrtemis 37 minutes ago
Comment by dallen33 4 hours ago
Comment by risyachka 4 hours ago
Comment by gadflyinyoureye 3 hours ago
Comment by kburman 2 hours ago
Comment by thibran 2 hours ago
Comment by varispeed 3 hours ago
Comment by rbren 2 hours ago
Comment by JohnMakin 1 hour ago
Why release this?
Comment by socratic_weeb 16 minutes ago
Comment by omega3 2 hours ago
Commercial inference providers serve Chinese models of comparable quality at 0.1x-0.25x. I think Anthropic realised that the game is up and they will not be able to hold the lead in quality forever so it's best to switch to value extraction whilst that lead is still somewhat there.
Comment by CharlesW 2 hours ago
"Comparable" is doing some heavy lifting there. Comparable to Anthropic models in 1H'25, maybe.
Comment by omega3 2 hours ago
But let's say for the sake of discussion Opus is much better - still doesn't justify the price disparity especially when considering that other models are provided by commercial inference providers and anthropics is inhouse.
Comment by cbg0 1 hour ago
Comment by xienze 2 hours ago
The problem here is people think AI benchmarks are analogous to say, CPU performance benchmarks. They're not:
* You can't control all the variables, only one (the prompt).
* The outputs, BY DESIGN, can fluctuate wildly for no apparent reason (i.e., first run, utter failure, second run, success).
* The biggest point, once a benchmark is known, future iterations of the model will be trained on it.
Trying to objectively measure model performance is a fool's errand.
Comment by synergy20 1 hour ago
Comment by therobots927 2 hours ago
This is already becoming apparent as users are seeing quality degrade which implies that anthropic is dropping performance across the board to minimize financial losses.
Comment by Bingolotto 3 hours ago
Comment by encoderer 3 hours ago
Re-ran the bake-off with 4.7 authoring and… gpt5.4 still clearly winning. Same skills, same prompts, same agents.md.
Comment by JimmaDaRustla 1 hour ago
Comment by bugsense 1 hour ago
Comment by saltyoldman 2 hours ago
But it looks like it's just creeping up. Probably because we're paying for construction, not just inference right now.
Comment by bcjdjsndon 3 hours ago
Comment by ricardobeat 3 hours ago
Feels like LLMs are devolving into having a single, instantly recognizable and predictable writing style.
Comment by stefan_ 3 hours ago
Comment by aray07 3 hours ago
https://platform.claude.com/docs/en/about-claude/pricing
So if you are generating more tokens, you are eating up your usage faster
Comment by CodingJeebus 3 hours ago
People love to throw around "this is the dumbest AI will ever be", but the corollary to that is "this is the most aligned the incentives between model providers and customers will ever be" because we're all just burning VC money for now.
Comment by HarHarVeryFunny 1 hour ago
That's one market segment - the high priced one, but not necessarily the most profitable one. Ferrari's 2025 income was $2B while Toyota's was $30B.
Maybe a more apt comparison is Sun Microsystems vs the PC Clone market. Sun could get away with high prices until the PC Clones became so fast (coupled with the rise of Linux) that they ate Sun's market and Sun went out of business.
There may be a market for niche expensive LLMs specialized for certain markets, but I'll be amazed if the mass coding market doesn't become a commodity one with the winners being the low cost providers, either in terms of API/subscriptions costs, or licensing models for companies to run on their own (on-prem or cloud) servers.
Comment by NickC25 3 hours ago
Please say this louder for everyone to hear. We are still at the stage where it is best for Anthropic's product to be as consumer aligned (and cost-friendly) as possible. Anthropic is loosing a lot of money. Both of those things will not be true in the near future.
Comment by BosunoB 3 hours ago
Comment by climike 38 minutes ago
Comment by texttopdfnet 3 hours ago
Comment by texttopdfnet 3 hours ago
Comment by throwaway613746 3 hours ago
Comment by storytellera 59 minutes ago
Comment by mikert89 3 hours ago
Comment by aray07 3 hours ago
Comment by schmookeeg 3 hours ago
Comment by rvz 3 hours ago
Gamblers (vibe-coders) at Anthropic's casino realising that their new slot machine upgrade (Claude Opus) is now taking 20%-30% more credits for every push of the spin button.
Problem is, it advertises how good it is (unverified benchmarks) and has a better random number generator but it still can be rigged (made dumber) by the vendor (Anthropic).
The house (Anthropic) always wins.
> People just want free tools forever?
Using local models are the answer to this if you want to use AI models free forever.
Comment by xd1936 4 hours ago
Comment by brokencode 3 hours ago
Much of the token usage is in reasoning, exploring, and code generation rather than outputs to the user.
Does making Claude sound like a caveman actually move the needle on costs? I am not sure anymore whether people are serious about this.
To me, caveman sounds bad and is not as easy to understand compared to normal English.
Comment by Majromax 4 hours ago
Comment by aray07 3 hours ago